TrialBridge
AI-powered pre-screening for clinical trials. Same rigor, zero drudgery.
HealthLangGraphDeepSeekPythonTsNextjs
🔴 Problem:-
India runs 3,000+ clinical trials. CTRI(Clinical Trial research Instt) lists them as unstructured text. Coordinators manually reconcile patient data across incompatible EDC formats—Medidata, Veeva, REDCap.
Same patient. Three IDs. Duplicate entries. Missing labs.
Result: 6 hours per batch. 40% screening error rate.
Coordinators spend 60% of their time on data wrangling, not clinical judgment.
🟢 Solution:-
Hence, I built 'TrialBridge':
a “Bridge” facilitating: connectivity between patients and trials, between India’s public health data patterns and CTRI listings, and between messy EDC exports and structured eligibility reasoning.
TrialBridge fixes the plumbing. So coordinators can do the doctoring.
• Ingests: Raw EDC exports (Medidata/Veeva/REDCap)
• Parses: Unstructured CTRI trial criteria
• Ranks: Patients by match confidence (high/med/low)
• Flags: Subjective criteria ("per investigator judgment") for MD review
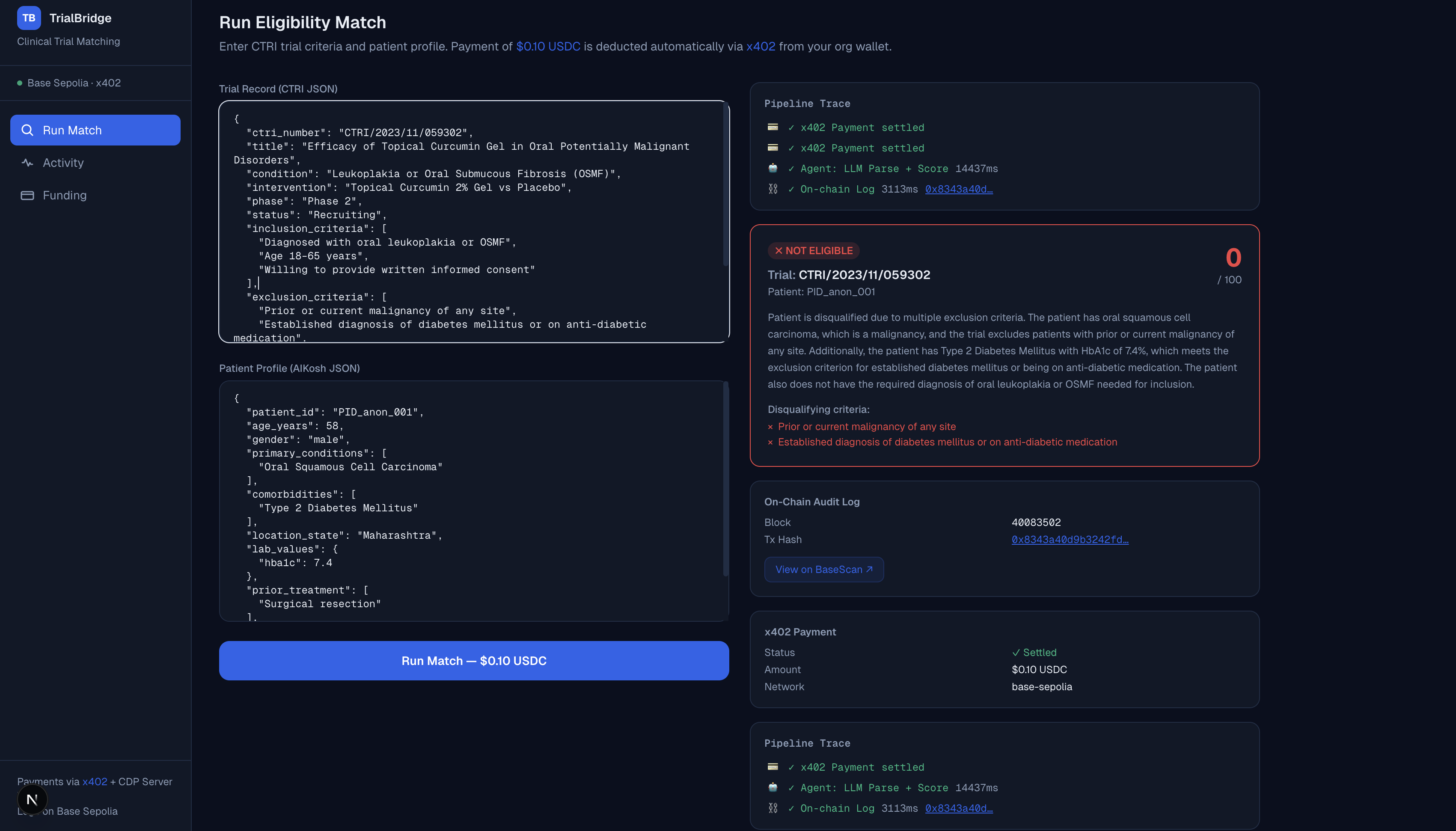
✅ TrialBridge is an AI-assisted decision-support platform designed to streamline the patient pre-screening process for clinical trials in India.
Under the hood, it employs a sophisticated multi-agent architecture orchestrated by LangGraph.
💠 One agent specializes in parsing unstructured trial criteria from sources like the Clinical Trials Registry – India (CTRI),
💠 while a data quality agent cleans, validates, and structures incoming patient data from various Electronic Data Capture (EDC) systems, including Medidata Rave, Veeva Vault, and REDCap.
This coordinated effort allows the system to score objective eligibility criteria and rank patients based on match confidence (high, medium, or low), providing a clear, evidence-based rationale for each recommendation.
🎯 A key design principle is the clear separation between automated scoring and necessary clinical oversight.
The platform intelligently identifies and flags subjective or ambiguous criteria—such as those requiring 'investigator judgment'—ensuring they are escalated for human review.
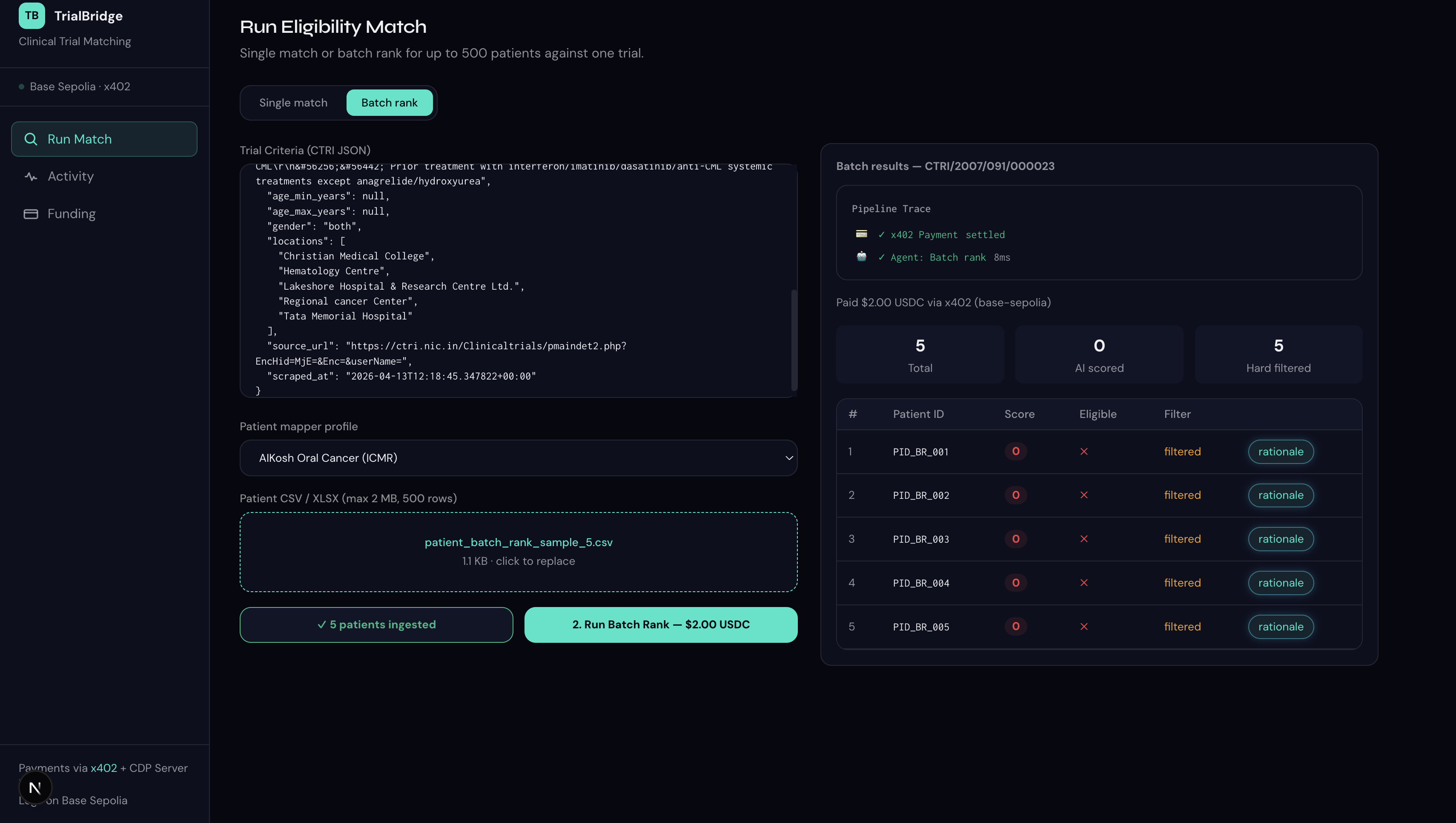
In addition to its core matching capabilities, TrialBridge provides comprehensive data quality reports, batch processing for up to 500 patients, a model performance dashboard, and a workflow for managing data clarification requests. By fixing the data 'plumbing,' TrialBridge empowers clinical coordinators to focus on patient care and critical decision-making rather than administrative drudgery.
Overview
Multi-EDC Data Ingestion: Automatically ingests and parses raw patient data from various Electronic Data Capture (EDC) systems, including Medidata Rave, Veeva Vault, and REDCap.
AI Agent Orchestration: Utilizes a LangGraph-based multi-agent system where specialized agents coordinate to parse trial criteria and clean patient data for accurate matching.
Intelligent Eligibility Scoring: Ranks patients by match confidence (high/medium/low) for specific trials, providing a detailed, transparent rationale for each AI-scored eligibility criterion.
Subjective Criteria Flagging: Intelligently identifies and flags ambiguous criteria (e.g., 'per investigator judgment') to ensure they are escalated for mandatory review by clinical staff.
Automated Data Quality Reports: Generates comprehensive reports on cohort completeness, field-level missingness, and duplicate entries to ensure data integrity before screening.
Batch Ranking Mode: Processes and ranks large cohorts of up to 500 patients simultaneously, dramatically accelerating the pre-screening workflow for entire patient groups.